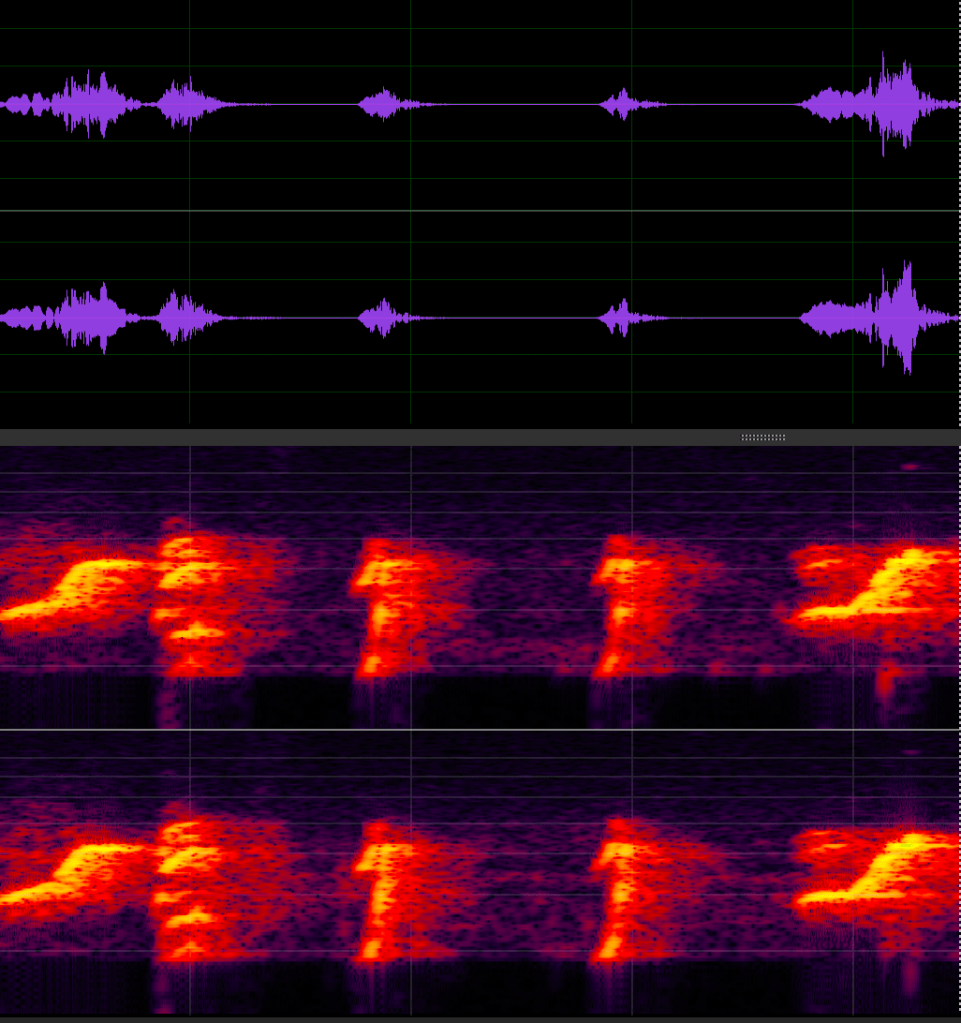
It began with a simple swim in the lake. I first heard an intriguing birdsong, filled with a fascinating array of musical ideas. The very next day, I returned to record its performance. Luckily, the bird was still there, and I captured a fairly good recording.
It was a European Reed Warbler.
Back home, I immediately set out to analyze the song. My initial approach involved meticulously notating every aspect of each sound: its duration, amplitude, pitch, and so on. I then developed a program to synthesize the sound. My idea was to go from analysis to synthesis, with the ultimate goal of playing my synthesized “fake” birdsong to the Merlin app, a tool known for its ability to recognize birds from their calls.
To my surprise, while the Merlin app instantly and without hesitation recognized the European Reed Warbler from my original recording of the actual bird, my synthesized version didn’t impress it at all – the app heard nothing.
This sent me back to the drawing board. My next approach will be to shift away from annotating every single sound from the bird, and instead, think in typologies. I can clearly hear (and see from the waveforms) that there’s a certain, seemingly limited, number of different kinds of sounds that the bird has in its repertoire. So now, the focus is on identifying these types, understanding their variabilities (in pitch, duration, amplitude, etc.), and analyzing how these sound types are typically combined (e.g., the number of repetitions, the adjacent sound types, etc.). This will likely involve an analysis akin to a Markov model.
Stay tuned for more updates on the project!.
Waveform and spectral frequencies of the European Reed Warbler’s singing.Waveform and spectral frequencies of my synthesised versionme listening to the song of the european reed warbler
My current artistic research explores the sonic expression of a forest’s metabolism. I’m using specialized microphones to capture the subtle vibrations and sounds produced by living organisms and ecological processes, and then translating these patterns into musical sound. My goal is to create a unique kind of concert experience where the forest itself becomes a musical collaborator.
This involves capturing the often inaudible sounds of life within the forest – the movements of roots, the activities of insects and microorganisms, and the flow of water and air. These expressions, often hidden from human perception, form distinct patterns that can be translated into data and used to generate synthesized sound. This process allows me to give a sonic voice to the trees, soil, and plants.
This research follows a period of exploration into bioelectricity, where I investigated how living organisms express themselves through electrical signals. However, practical considerations and the desire for a more portable setup led me to investigate vibrations and sound as alternative expressions of life.
Finding the Right Tools
To “listen” to the forest, I needed the right tools. After considering various parameters like humidity and pressure, I focused on capturing the vibrations and sounds of the soil, trees, and plants. This led me to two microphones: the Jez Riley French ‘ECOUTIC’ contact microphone and the Interharmonic ‘GEOPHON.’
Initial tests with the ECOUTIC in my garden proved disappointing. While recording the compost bin and an apple tree, the microphone captured a wide range of ambient sounds, making it difficult to isolate the sounds emanating from the source I was probing.
Hoping for a more focused approach, I switched to the GEOPHON. Unlike the contact-based ECOUTIC, the GEOPHON utilizes a magnet and a coil of copper wire, potentially making it less sensitive to ambient noise. Initial tests in a quiet forest environment were more promising.
Decoding the Sounds of Life
I collected recordings from various sources – trees, soil, plants, mushrooms, and decaying wood. While these sounds were largely unintelligible to human ears, I could perceive distinct differences between the recordings from each location. However, knowing that the GEOPHON captures frequencies below human hearing, I needed a way to analyze and interpret these inaudible sounds.
Using MaxMSP software, I’m experimenting with two analysis techniques:
Amplitude Analysis: I divided the sound spectrum into 10 Hz windows and analyzed the amplitude variations within each window. This created 40 distinct “frequency bands,” each with its own fluctuating amplitude. I then translated these fluctuations into synthesized sound, with each band represented by a sine wave at a specific frequency. The result is a droning sound with a subtly shifting timbre, reflecting the dynamic activity within each frequency band.
Brightness and Noisiness: Using a MaxMSP object called “Analyzer,” I tracked the brightness and noisiness of the sounds. This provides a stream of data for each parameter, revealing significant differences between the sound sources. I then used these parameters to control the sonification, with brightness influencing the waveform (from sawtooth to sine wave) and noisiness affecting the waveform’s modulation. This creates a dynamic sonic landscape that reflects the unique character of each sound source.
Continuing the Exploration
I’m eager to continue refining my methods and exploring the sonic world of the forest.
This research is ongoing. I’ve created a video showcasing some of my initial analysis and sonification results:
I welcome your feedback and thoughts on this research. Please feel free to share your insights in the comments below.
We are nearing our objective of enabling our computer to interact with a live musician in a manner that closely resembles the interaction with another musician. In this fourth vlog, we explore the user interface developed by Samuel Peirce-Davies, which employs the ml.markov object to learn music from MIDI files. Our aim is to extend this functionality to accommodate music played by a live musician, which we’ve found requires certain adjustments.
Specifically, we’ve discovered that the realm of rhythm, or the temporal aspect of music, necessitates a distinct approach beyond the straightforward, millisecond-based logic. The key lies in thinking in terms of PROPORTIONS. Essentially, we’re dealing with the relationship between pulse and rhythm. This relationship needs to be quantized into a limited number of steps or index numbers that can be input into the Markov model.
Vlog 4
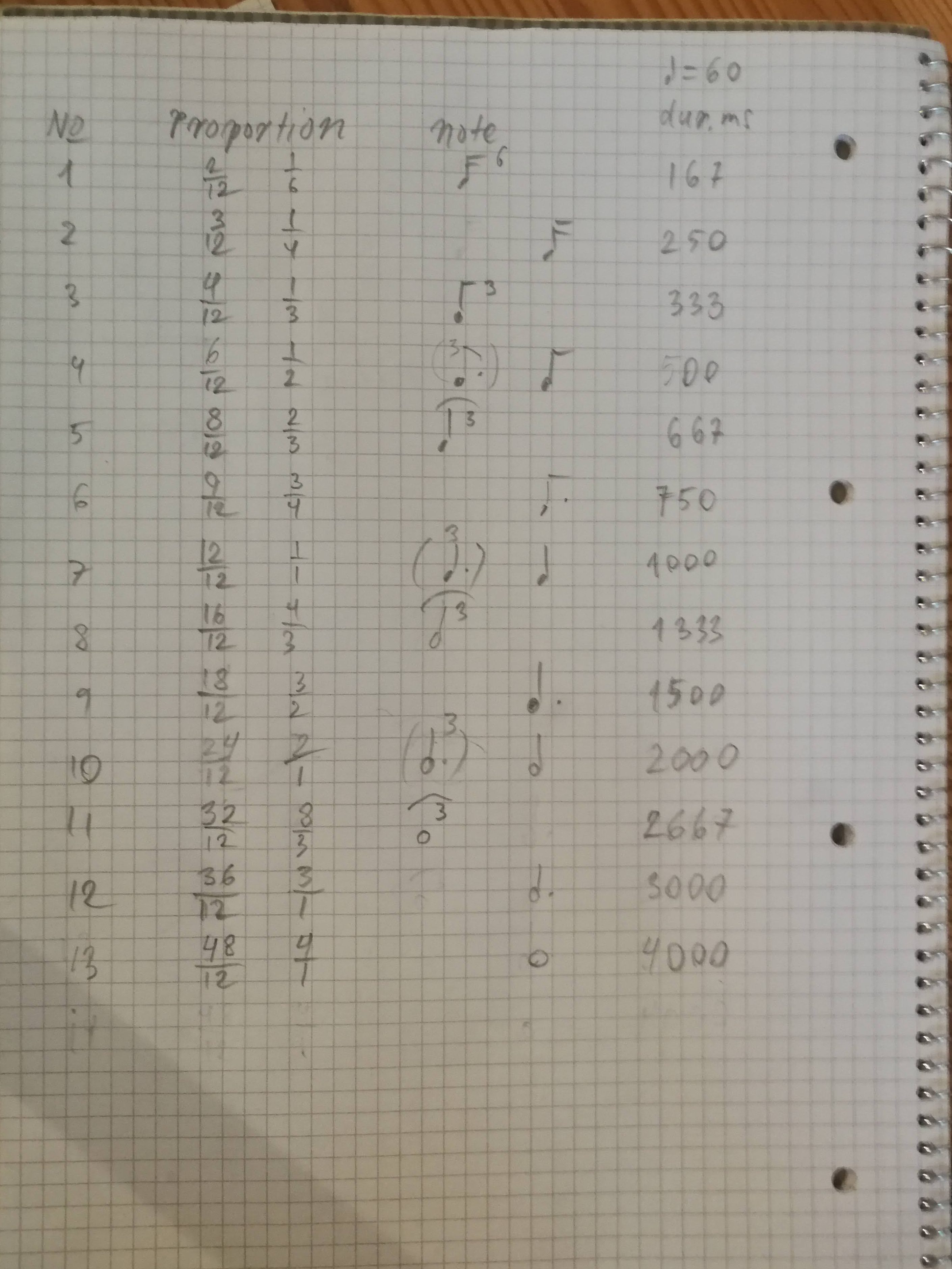
To achieve this, I’ve employed what might best be described as a fractal approach. We’re investigating the interaction between pulse and rhythm, moving away from a linear methodology that divides the pulse into equally spaced steps. Instead, we aim to determine the proportion, leading us to work with a list of fractions that divide the beat into segments like 1/6, 1/4, 1/3, 1/2, and so on.
By setting the maximum rhythmic duration to 4/1 of a beat, we have distilled the complexity down to just 13 different index values. This is in contrast to an equal steps approach, which would yield 48 index values if each beat were divided into 12 equal parts.
Consider whether you would truly notice a difference between a duration of 48/48 versus 47/48. Likely not, which illustrates why 13 index numbers are more meaningful to the Markov model compared to 48. This is especially relevant when considering Samuel’s approach, where any duration, measured in milliseconds, could potentially be integrated into the Markov model.
Sketch to a fractal concept of rhythmical proportions, turning rhythm into 13 index values to be fed into the markov model.
Update, 2024-02-17
After quite some messing around with geogebra, sheets, papir&pencil, I’ve come up with a visual representation of the fractal like structure of the duration index values.
It’s based on the series of duration fractions dividing the beat into triplets and quadruplets following the logic of double value, then dotted value, etc. Here is the series of fractions: 2/12 3/12 4/12 6/12 8/12 9/12 12/12 16/12 18/12 24/12 32/12 36/12 48/12
And here is how these fractions will look when ‘translated’ into squares with a common center:
Notice the self similarity (IE fractal-ness) of the proportion between the blue, pink and brown squares at each level.
The people who have written it out have really done a lot of effort, including pedagogical graphics like this one:
YOUR composition teacher
Unfortunately, the text is a tour de force through all the typical misconceptions you would meet in any presentation about music and composition in education. It seems futile to start and edit the article, – after all it is conform to the most widespread ideas about the subject, so my only reasonable option was to give this comment in the discussion:
“This article is a brilliant example of how to confuse people and block their musical creativity. It stems from the misunderstanding that the analysis of existing music, underlying what we call music theory, IS in fact music
However, music does not come from nowhere, it is embedded in a CONTEXT.
Explaining people how to compose by showing them scales, chords and instruments is like explaining someone how to communicate with another human being by giving them an alphabet and asking them to know the sequence of the letters by heart.
This musical autism is lamentably very widespread, and it is reproduced in education all the way to the conservatories. Being at a higher level of studies does not bring clarification but simply adds complexity to the same confusion.
Using sound as a means of expression MIGHT involve instruments, chords, scales, tones etc, but basically the capacity of composing is rooted in our everyday lives. Composing is something that we humans do all the time. As a collective we build a common world, an assemblage, and one of the most fundamental means we possess to that end is our ability to use language.
In language, we are capable of expressing and perceiving the most minuscule nuances in our interactions through sound.
THIS should be the message to someone asking how to compose music, that you are doing it already, and you can depart from this activity and prolong and extend it into sequences of sound. Use all kinds of existing music and sounds around you, choose according to your intuition, be a whole human being, use your voice and body as impulse giver. Remix, reuse, hack your way into existing technologies – digital as well as acoustic instruments, and build forms in sound inspired by everyday life events, social scripts and narratives.”